在CRT预估问题中,我们经常会遇到很多离散特征,常用的处理方式就是将其转化成onehot向量,或者是multi-hot,但是不可避免的高维的稀疏矩阵。解决这个问题的办法就是通过嵌入的方式进行转化。 然后通过得到的嵌入向量通过FM的关系进行建模学习特征之间的交互关系。但是FM只能够学习二阶的特征交叉,无法学习更高阶特征之间的关系。因此又有人提出通过MLP来学习更高阶的特征关系。
因此FM和DNN也成为了CRT预估问题的最主流的方法。但是由于FM和DNN的结合关系,分为两种,并行结构和串行结构,而本文提到的AFM模型就有是串型结构中的一种网络结构。 这种模型的作者和NFM的作品是同一个作者。对于NFM本质上还是基于FM,FM会让一个特征固定一个特定的向量,当这个特征与其他特征做交叉时,都是用同样的向量去做计算。这个是很不合理的,因为不同的特征之间的交叉,重要程度是不一样的。因此,学者们提出了AFM模型(Attentional factorization machines),将attention机制加入到我们的模型中,关于AFM的知识,接下来我们来看看具体的内容。
NFM模型介绍
因为AFM是在FM的基础上进行改进的,因此我们首先简单的回顾一下FM模型,FM模型是用隐向量的内积来表示二次项的参数。其中隐向量的个数是n个,代表特征在one-hot之后的特征总数。下面是FM的公式
接下来就是FM的简化过程
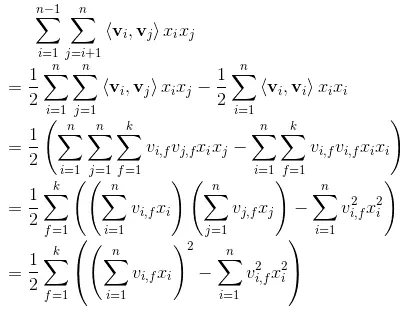
从结果可以看出,我们可以得到一个k维的向量,这个向量的每个维度就是每两个特征的交叉结果。FM模型是将这k为值求和,代表特征交叉的结果。 但是不难发现在FM中任意两个特征进行交叉的时候,其中的嵌入向量都是一样的。这就很不合理了,因为不同的特征之间做交叉,重要的程度是不一样的。 如何体现这种重要程度,之前介绍的FFM模型是一个方案。另外,结合了attention机制的AFM模型,也是一种解决方案。
这里所谓的attention机制,我们要知道的就是根据不同的特征进行交叉的是时候,类似于做个加权平均,其中attention的值就是其权重,来决定不同特征之间的一个中重要程度。
这里的我们就可以先来看看AFM模型预测的公式:
其中$\bigodot$ 符号就是element-wise product,即每一位对应相乘。因此,我们在求和以后会得到一个k维的列向量,在乘以一个p向量,最终会得到一个具体的数值。
通过公式我们还可以看出来,AFM和FM的前两个部分是一样的,表示这线性部分,而后一项这是AFM的核心内容,通过下面一组网络得到:
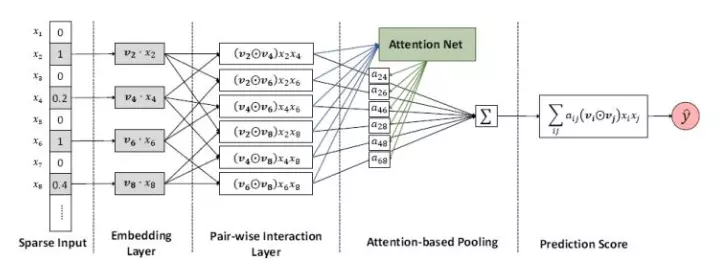
图中前三部分其实和FM中的是一样的,最主要的是后两项。这部分就是所说的注意力网络,我们来看看其内在是数学含义:
通过上面的公式,我们知道式子1中的aij其实就是通过FM二次项做输入,通过一层的隐藏层网络,通过激活函数ReLu,然后得到不同特征交叉的时候的一个权重。 我们可以看出,aij其实通过一个softmax 所以其值在0-1内,就是这里sum pooling中的各项权重。
接下来就是P这个地方。我的理解是,这部分也属于一个参数,主要是为了在将所有特征交叉得到的结果在进行一个不同成程度的相加。这样和p相乘之后,就会将k维 的向量转化成一个具体的数值。
对于训练这个模型,文中采用的是MSE ,同时为了减少噪音的影响,加入了正则化项,于是就可以得到损失函数了:
以上就是AFM的基本内容了,有什么不对的地方,欢迎大家来指出。
tensorflow实现部分
这里只是对AFM模型中的一些关键部分讲解一下,如想看详细代码的可以参考这个github。
模型的输入部分
这里是模型的几个主要的输入部分
self.feat_index = tf.placeholder(tf.int32,
shape=[None,None],
name='feat_index')
self.feat_value = tf.placeholder(tf.float32,
shape=[None,None],
name='feat_value')
self.label = tf.placeholder(tf.float32,shape=[None,1],name='label')
self.dropout_keep_deep = tf.placeholder(tf.float32,shape=[None],name='dropout_deep_deep')
feat_index是特征的一个序号,主要用于通过embedding_lookup选择我们的embedding。feat_value是对应的特征值,如果是离散特征的话,就是1,如果不是离散特征的话,就保留原来的特征值。label是实际值。还定义了dropout来防止过拟合。
Embedding Layer
这里是根据feat_index选择对应的weights[‘feature_embeddings’]中的embedding值,然后再与对应的feat_value相乘就可以了(就是公式中的xivi):
# Embeddings
self.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * K
feat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1])
self.embeddings = tf.multiply(self.embeddings,feat_value) # N * F * K
权重的构建
第一部分是嵌入层的一个权值:
def _initialize_weights(self):
weights = dict()
#embeddings
weights['feature_embeddings'] = tf.Variable(
tf.random_normal([self.feature_size,self.embedding_size],0.0,0.01),
name='feature_embeddings')
weights['feature_bias'] = tf.Variable(tf.random_normal([self.feature_size,1],0.0,1.0),name='feature_bias')
weights['bias'] = tf.Variable(tf.constant(0.1),name='bias')
第二部分是Attention部分的权重,就是公式2中的所有参数,分别是w,b,h,p
weights[‘attention_w’] 的维度为 K * A, weights[‘attention_b’] 的维度为 A, weights[‘attention_h’] 的维度为 A, weights[‘attention_p’] 的维度为 K * 1
# attention part
glorot = np.sqrt(2.0 / (self.attention_size + self.embedding_size))
weights['attention_w'] = tf.Variable(np.random.normal(loc=0,scale=glorot,size=(self.embedding_size,self.attention_size)),
dtype=tf.float32,name='attention_w')
weights['attention_b'] = tf.Variable(np.random.normal(loc=0,scale=glorot,size=(self.attention_size,)),
dtype=tf.float32,name='attention_b')
weights['attention_h'] = tf.Variable(np.random.normal(loc=0,scale=1,size=(self.attention_size,)),
dtype=tf.float32,name='attention_h')
weights['attention_p'] = tf.Variable(np.ones((self.embedding_size,1)),dtype=np.float32)
Attention Net
这部分的主要就是公式2部分,然后我们来实现一下。首先是前面embedding之后得到的向量,即vixi,维度是N*K, 接下来就是做element-wise-product,通过循环,将所有的特征交叉进行相加,此时得到的维度是(F *(F-1)/2) * N * F, 因此我们需要一个转置操作,来得到维度为 N * (F * F - 1 / 2) * K的element-wize-product结果。
element_wise_product_list = []
for i in range(self.field_size):
for j in range(i+1,self.field_size):
element_wise_product_list.append(tf.multiply(self.embeddings[:,i,:],self.embeddings[:,j,:])) # None * K
self.element_wise_product = tf.stack(element_wise_product_list) # (F * F - 1 / 2) * None * K
self.element_wise_product = tf.transpose(self.element_wise_product,perm=[1,0,2],name='element_wise_product') # None * (F * F - 1 / 2) * K
得到了element-wise-product之后,我们接下来计算隐藏层部分, 计算之前,我们需要先对element-wise-product进行reshape,将其变为二维的tensor,在计算完之后再变换回三维tensor,此时的维度为 N * (F * F - 1 / 2) * A:
self.attention_wx_plus_b = tf.reshape(tf.add(tf.matmul(tf.reshape(self.element_wise_product,shape=(-1,self.embedding_size)),
self.weights['attention_w']),
self.weights['attention_b']),
shape=[-1,num_interactions,self.attention_size]) # N * ( F * F - 1 / 2) * A
然后我们在计算一个隐藏层的部分,此时维度为N * ( F * (F - 1) / 2) * 1
self.attention_exp = tf.exp(tf.reduce_sum(tf.multiply(tf.nn.relu(self.attention_wx_plus_b),
self.weights['attention_h']),
axis=2,keep_dims=True)) # N * ( F * F - 1 / 2) * 1
然后就是执行softmax的部分
self.attention_exp_sum = tf.reduce_sum(self.attention_exp,axis=1,keep_dims=True) # N * 1 * 1
self.attention_out = tf.div(self.attention_exp,self.attention_exp_sum,name='attention_out') # N * ( F * F - 1 / 2) * 1
最后,我们计算得到经attention net加权后的二次项结果,此时就是得到一个具体的值了:
self.attention_x_product = tf.reduce_sum(tf.multiply(self.attention_out,self.element_wise_product),axis=1,name='afm') # N * K
self.attention_part_sum = tf.matmul(self.attention_x_product,self.weights['attention_p']) # N * 1
模型最终的预测输出
为了得到预测输出,除Attention part的输出外,我们还需要两部分,分别是偏置项和一次项:
# first order term
self.y_first_order = tf.nn.embedding_lookup(self.weights['feature_bias'], self.feat_index)
self.y_first_order = tf.reduce_sum(tf.multiply(self.y_first_order, feat_value), 2)
# bias
self.y_bias = self.weights['bias'] * tf.ones_like(self.label)
# out
self.out = tf.add_n([tf.reduce_sum(self.y_first_order,axis=1,keep_dims=True),
self.attention_part_sum,
self.y_bias],name='out_afm')
至此就是AFM的全部内容了,总结一下,不难看出AFM只是在FM的基础上添加了attention的机制,但是实际上,由于最后的加权累加,二次项并没有进行更深的网络去学习非线性交叉特征,所以AFM并没有发挥出DNN的优势,也许结合DNN可以达到更好的结果。