在CRT预估问题中,我们经常会遇到很多离散特征,常用的处理方式就是将其转化成onehot向量,或者是multi-hot,但是不可避免的高维的稀疏矩阵。解决这个问题的办法就是通过嵌入的方式进行转化。 然后通过得到的嵌入向量通过FM的关系进行建模学习特征之间的交互关系。但是FM只能够学习二阶的特征交叉,无法学习更高阶特征之间的关系。因此又有人提出通过MLP来学习更高阶的特征关系。
因此FM和DNN也成为了CRT预估问题的最主流的方法。但是由于FM和DNN的结合关系,分为两种,并行结构和串行结构,而本文提到的NFM模型就有是串型结构中的一种。 这种模型其实个DeepFM很相似,只是在其基础上进行了简单的修改。接下来我就详细的解释一下。
NFM模型介绍
刚刚说NFM是在DeepFM的一个简单修改,所以简单的回顾一下FM模型,FM模型是用隐向量的内积来表示二次项的参数。其中隐向量的个数是n个,代表特征在one-hot之后的特征总数。下面是FM的公式
接下来就是FM的简化过程
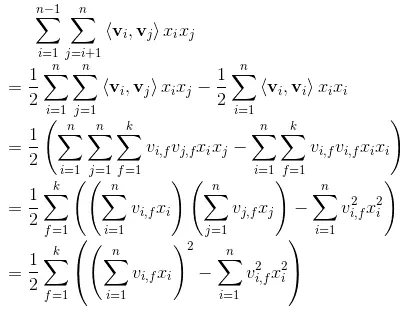
从结果可以看出,我们可以得到一个k维的向量,这个向量的每个维度就是每两个特征的交叉结果。FM模型是将这k为值求和,代表特征交叉的结果。但是NFM采用的这是将每一个维度作为神经网络的输入。
因此可以得到NFM的预测公式是:
其中这个f(x)就是NFM的核心部分,用于建模特征交叉。NFM的整体结构如下图所示:
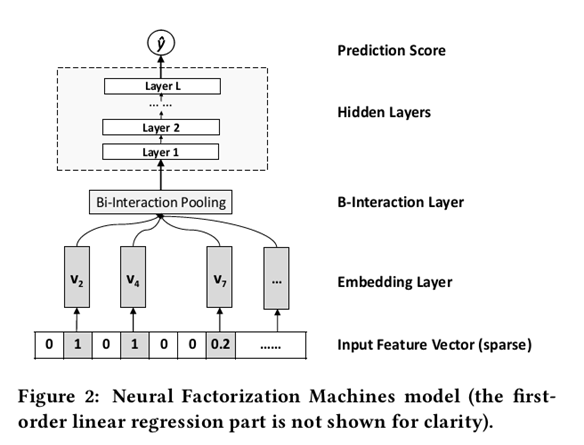
Embedding Layer
这部分类似于许多模型中的样子,将离散特征通过Embedding方式得到一个向量表示,不过这里不对连续特征记性处理。
Bi-Interaction Layer
这一层的操作其实就是很简单的pooling操作,将隐向量和x相乘,再把多个向量转化成一个向量,如:
这里xi,xj是特征向量的取值,vi,vj是对应的嵌入向量。然后使之对应位相乘,所有的特征任意组合,对应位置相乘都会得到一个新的向量,将这些向量相加,最后会得到一个向量,这就是BI-interaction的输出。
注:在原始的FM中会将Bi-Interaction得到的结果相加得到一个值,但这好比就是一个线性模型,权重是1。NFM模型而是将这些输出值送入隐藏层中去学习更高阶的特征组合,增强其非线性能力。 参考FM的优化方法,化简如下:
Hidden Layer
这里就是DNN部分,没什么特别的了。
Prediction Layer
在进行多层训练之后,将最后一层的输出求和同时加上一次项和偏置项,就得到了我们的预测输出:
这里就差不多就是全部内容了,其实可以看出这里依旧是FM和DNN组合的问题。不过NFM也有些自己的特点:
1、NFM核心就是在NN中引入了Bilinear Interaction(Bi-Interaction) pooling操作。基于此,NN可以在low level就学习到包含更多信息的组合特征。
- NFM模型将FM与神经网络结合以提升FM捕捉特征间多阶交互信息的能力。根据论文中实验结果,NFM的预测准确度相较FM有明显提升,并且与现有的并行神经网络模型相比,复杂度更低。
tensorflow实现部分
这里提出一些关键部分,简单的实现了一下NFM模型。
模型的输入部分
self.feat_index = tf.placeholder(tf.int32,
shape=[None,None],
name='feat_index')
self.feat_value = tf.placeholder(tf.float32,
shape=[None,None],
name='feat_value')
self.label = tf.placeholder(tf.float32,shape=[None,1],name='label')
self.dropout_keep_deep = tf.placeholder(tf.float32,shape=[None],name='dropout_deep_deep')
feat_index是特征的一个序号,主要用于通过embedding_lookup选择我们的embedding。feat_value是对应的特征值,如果是离散特征的话,就是1,如果不是离散特征的话,就保留原来的特征值。label是实际值。还定义了dropout来防止过拟合。
Embedding Layer
这里是根据feat_index选择对应的weights[‘feature_embeddings’]中的embedding值,然后再与对应的feat_value相乘就可以了(就是公式中的xivi):
# Embeddings
self.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * K
feat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1])
self.embeddings = tf.multiply(self.embeddings,feat_value) # N * F * K
Bi-Interaction Layer
直接根据化简后的结果进行计算,得到一个K维的向量(这里和FM的区别就是差一个redunce_sum):
# sum-square-part
self.summed_features_emb = tf.reduce_sum(self.embeddings, 1) # None * k
self.summed_features_emb_square = tf.square(self.summed_features_emb) # None * K
# squre-sum-part
self.squared_features_emb = tf.square(self.embeddings)
self.squared_sum_features_emb = tf.reduce_sum(self.squared_features_emb, 1) # None * K
# second order
self.y_second_order = 0.5 * tf.subtract(self.summed_features_emb_square, self.squared_sum_features_emb)
最终的输出
我们还需要两部分,分别是偏置项和一次项:
# first order term
self.y_first_order = tf.nn.embedding_lookup(self.weights['feature_bias'], self.feat_index)
self.y_first_order = tf.reduce_sum(tf.multiply(self.y_first_order, feat_value), 2)
# bias
self.y_bias = self.weights['bias'] * tf.ones_like(self.label)
# out
self.out = tf.add_n([tf.reduce_sum(self.y_first_order,axis=1,keep_dims=True),
tf.reduce_sum(self.y_deep,axis=1,keep_dims=True),
self.y_bias])